
User experience
Article Wikipedia : https://en.wikipedia.org/wiki/User_experience
Journaux liées à cette note :
J'ai découvert AIChat, alternative à llm cli
Dans ce thread, #JaiDécouvert AIChat (https://github.com/sigoden/aichat), une alternative à llm (cli) codée en Rust.
AIChat is an all-in-one LLM CLI tool featuring Shell Assistant, CMD & REPL Mode, RAG, AI Tools & Agents, and More.
En parcourant le README.md, j'ai l'impression que AIChat propose une meilleure UX que llm (cli).
Je constate aussi que AIChat offre plus de fonctionnalités que llm (cli) :
- AI Tools & MCP
- AI Agents
- LLM Arena
- La partie RAG semble plus avancée
Ce qui attire le plus mon attention, c'est le sous-projet llm-functions qui, d'après ce que j'ai lu, permet de créer très facilement des tools en Bash, Python ou Javascript. Exemples :
J'ai hâte de tester ça 🙂 ( #JaimeraisUnJour ).
Par contre, llm-functions ne semble pas encore permettre la configuration de Remote MCP server.
Je suis aussi intéressé par cette issue : TUI for managing, searching, and switching between chat sessions.
Un point qui m'inquiète un peu : le projet semble peu actif ces derniers mois.
Journal du vendredi 21 novembre 2025 à 12:03
Dans ce thread, #JaiDécouvert OpenCode (https://github.com/sst/opencode) qui semble être une alternative à Aider et Claude Code.
Après avoir parcouru la documentation, j'ai l'impression qu'OpenCode propose des fonctionnalités et une User experience plus avancées qu'Aider.
Le projet est récent (démarré en mars 2025) et publié sous licence MIT.
D'après le footer du site de documentation, je comprends qu'OpenCode est développé par l'entreprise Anomaly, financée par du Venture capital.
#JaiLu ce commentaire à propos d'OpenCode dans les issues d'Aider.
En cherchant sur Hacker News, je suis tombé sur ce thread de juillet 2025.
J'ai retenu ce commentaire :
Two big differences:
opencode is much more "agentic": It will just take off and do loads of stuff without asking, whereas aider normally asks permission to do everything. It will make a change, the language server tells it the build is broken, it goes and searches for the file and line in the error message, reads it, and tries to fix it; rinse repeat, running (say) "go vet" and "go test" until it doesn't see anything else to do. You can interrupt it, of course, but it won't wait for you otherwise.
aider has much more specific control over the context window. You say exactly what files you want the LLM to be able to see and/or edit; and you can clear the context window when you're ready to move on to the next task. The current version of opencode has a way to "compact" the context window, where it summarizes for itself what's been done and then (it seems) drops everything else. But it's not clear exactly what's in and out, and you can't simply clear the chat history without exiting the program. (Or if you can, I couldn't find it documented anywhere.)
Je retiens donc qu'Aider offre un contrôle plus précis qu'OpenCode. OpenCode fonctionne de manière plus autonome.
Pour ma part, je préfère contrôler finement les actions d'un AI code assistant sur mon code, à la fois pour comprendre ses interventions et pour gérer ma consommation de tokens.
Je n'ai pas envie de tester OpenCode pour le moment, je vais continuer avec Aider.
Journal du mercredi 24 septembre 2025 à 18:03
Dans ce billet du blog de Bluefin #JaiDécouvert Bazaar (https://github.com/kolunmi/bazaar).
Bazaar is a new app store for GNOME with a focus on discovering and installing applications and add-ons from Flatpak remotes, particularly Flathub ...
Bazaar is fast and highly multi-threaded, guaranteeing a smooth experience in the user interface. You can queue as many downloads as you wish and run them while perusing Flathub's latest releases. This is due to the UI being completely decoupled from all backend operations.
Bazaar est une alternative à l'application officielle GNOME nommée gnome-software.
Contrairement à gnome-software qui est basée sur PackageKit et gère différents types de packages (RPM, DEB, Flatpak, Snap, etc.), Bazaar a un périmètre plus limité et se concentre exclusivement sur les packages Flatpak.
Dans un premier temps, je me suis demandé quel était l'intérêt de créer une nouvelle GUI pour installer des packages, pourquoi l'auteur n'a pas choisi de contribuer à gnome-software ?
J'ai trouvé une réponse dans ce thread.
Bazaar est une application avec une vision tranchée :
- support uniquement le repository Flathub (qui contient seulement des packages Flatpak) ;
- mise en avant de solution pour faire des donations.
Cette vision a permis à l'auteur de créer Bazaar en mai 2025, à partir de zéro, avec une implémentation plus direct (pas de support PackageKit…).
Cela lui a permis aussi de se consacrer fortement sur l'expérience utilisateur.
Après avoir testé l'application, je constate que contrairement à gnome-software, toutes les tâches s'exécutent de manière asynchrone. À la différence de gnome-software, Bazaar évite de recharger constamment l'index des packages après chaque opération , ce qui rend l'expérience utilisateur excellente 🙂.
Bazaar is fast and highly multi-threaded, guaranteeing a smooth experience in the user interface. You can queue as many downloads as you wish and run them while perusing Flathub's latest releases. This is due to the UI being completely decoupled from all backend operations.
Je tiens tout de même à préciser que la version 49 de gnome-software a fait des progrès à ce sujet, un gros travail de refactoring a été fait sur 3 ans (73 Merge Request 😮) pour apporter le support de threading dans gnome-software.
Je pense utiliser Bazaar dans Projet 26 - "Expérimentation de migration de deux utilisateurs grand public vers des laptops sous Fedora".
J'ai pris conscience de l'intérêt de DMARC et de l'alignement SPF et DKIM
Dans le contexte de ma mission Freelance, je poursuis l'actualisation de mes compétences en délivrabilité d'e-mail. J'en profite pour rédiger une note sur DMARC.
DMARC existe depuis 2012, mais je n'avais jamais vraiment creusé le sujet. Je l'avais seulement survolé. Jusqu'à récemment, je n'avais en tête que la fonction "monitoring" :
Sans avoir mesuré l'importance de la partie policy :
If the email fails the check, depending on the instructions held within the DMARC record the email could be delivered, quarantined or rejected.
Je pensais naïvement que les vérifications SPF et DKIM réalisées par les email service providers étaient suffisantes.
Je n'avais pas réalisé l'importance du SPF alignment and DKIM alignment.
Le problème vient du fait que SPF et DKIM vérifient le domaine contenu dans MailFrom (connu aussi sous les noms Return-Path, Bounce Address, ou Envelope From). Ces contrôles s'assurent que le serveur émetteur peut légitimement envoyer des emails pour ce domaine et que le message n'a pas été modifié durant le transport.
Cependant, ces vérifications ne protègent pas du spoofing. Les clients mail n'affichent pas le champ MailFrom, mais le champ From:. Un attaquant peut donc envoyer un email avec un domaine validé par SPF et DKIM tout en utilisant un champ From: qui ne lui appartient pas.
L'alignement vérifie que le domaine utilisé pour les contrôles SPF et DKIM correspond au domaine du champ From:.
Si les domaines diffèrent, le serveur receveur exécute la politique DMARC : reject pour rejeter l'email ou quarantine pour le diriger vers les spam.
De plus, j'ai découvert que DMARC était devenu petit à petit obligatoire :
Comply with email providers requirements: in 2024, Google and Yahoo started requiring DMARC on incoming mail from high-volume senders, and Microsoft followed in 2025. If you send emails to Gmail addresses, you may be affected by this. Even if you aren’t, this is likely just Google’s and Yahoo’s first step in a path to enforce DMARC checks on all incoming email, and organizations must prepare in advance.
Je viens de réaliser que c'est sans doute à cause de l'absence de DMARC sur mon domaine (stephane-klein.info) qui explique pourquoi en janvier 2024, un ami ne recevait aucun de mes mails sur sa boite mail Orange.
$ dig TXT _dmarc.stephane-klein.info +short
;; communications error to 127.0.0.53#53: timed out
Il y a quelques jours, je me suis lancé dans la configuration DMARC de mon domaine.
J'ai commencé par chercher des services de DMARC reporting.
Je suis dans un premier temps tombé sur Google Postmaster Tools, mais celui-ci est limité aux boites mails Gmail.
En cherchant des outils d'inbox placement dans le Subreddit EmailMarketing, j'ai découvert GlockApps qui permet aussi de faire du DMARC reporting.
Ensuite, en étudiant l'excellente documentation dmarc.wiki, j'ai découvert le service DMARCwise réalisé par un Indie Hacker italien : Matteo Contrini.
Il est gratuit pour un usage personnel :
J'ai testé ce service et je l'ai trouvé excellent !
Au départ, j'ai commencé par activer graduellement DMARC comme conseillé ici :
$ dig TXT _dmarc.stephane-klein.info +short
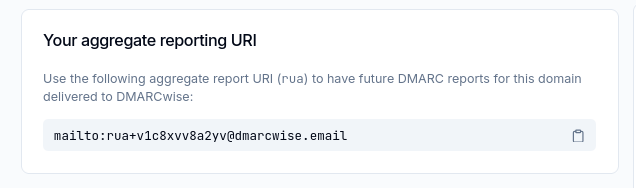
"v=DMARC1; p=none; rua=mailto:rua+v1c8xvv8a2yv@dmarcwise.email;"
L'adresse mail de collecte rua+v1c8xvv8a2yv@dmarcwise.email m'a été donné par DMARCwise :
J'ai ensuite lancé un "DMARC diagnostics" :
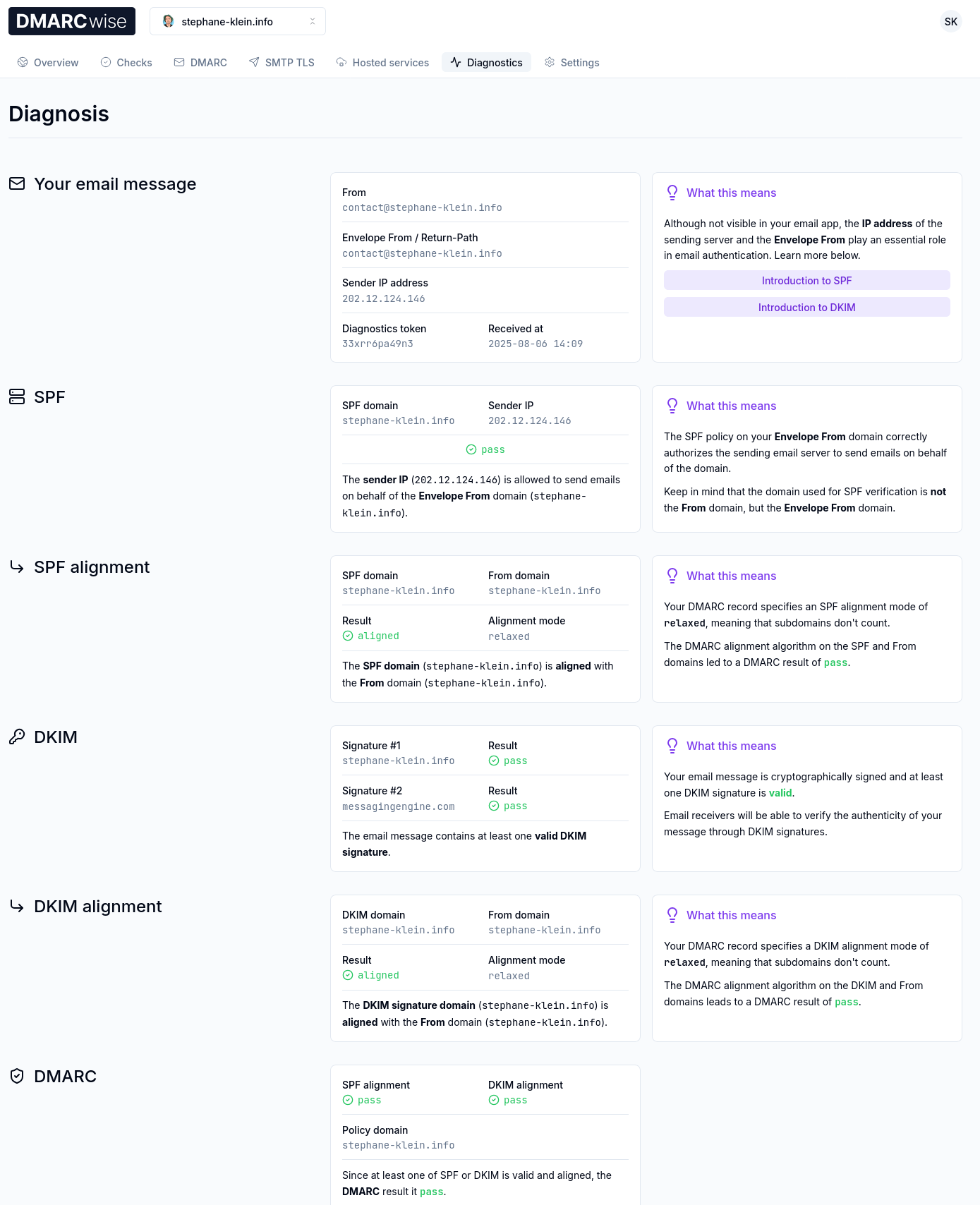
Et j'ai constaté que tout était parfaitement configuré :
Après réflexion, étant donné que je suis le seul émetteur d'e-mail pour mon domaine, j'ai jugé que je pouvais directement passer de pas de policy (p=none) à p=reject; pct=100;.
$ dig TXT _dmarc.stephane-klein.info +short
"v=DMARC1; p=reject; pct=100; rua=mailto:rua+v1c8xvv8a2yv@dmarcwise.email;"
Après 3 jours d'utilisation de DMARCwise, l'expérience utilisateur me plaît énormément. Il me semble que tout est soigneusement conçu, Matteo Contrini fait clairement attention aux détails !
Voici à quoi cela ressemble :
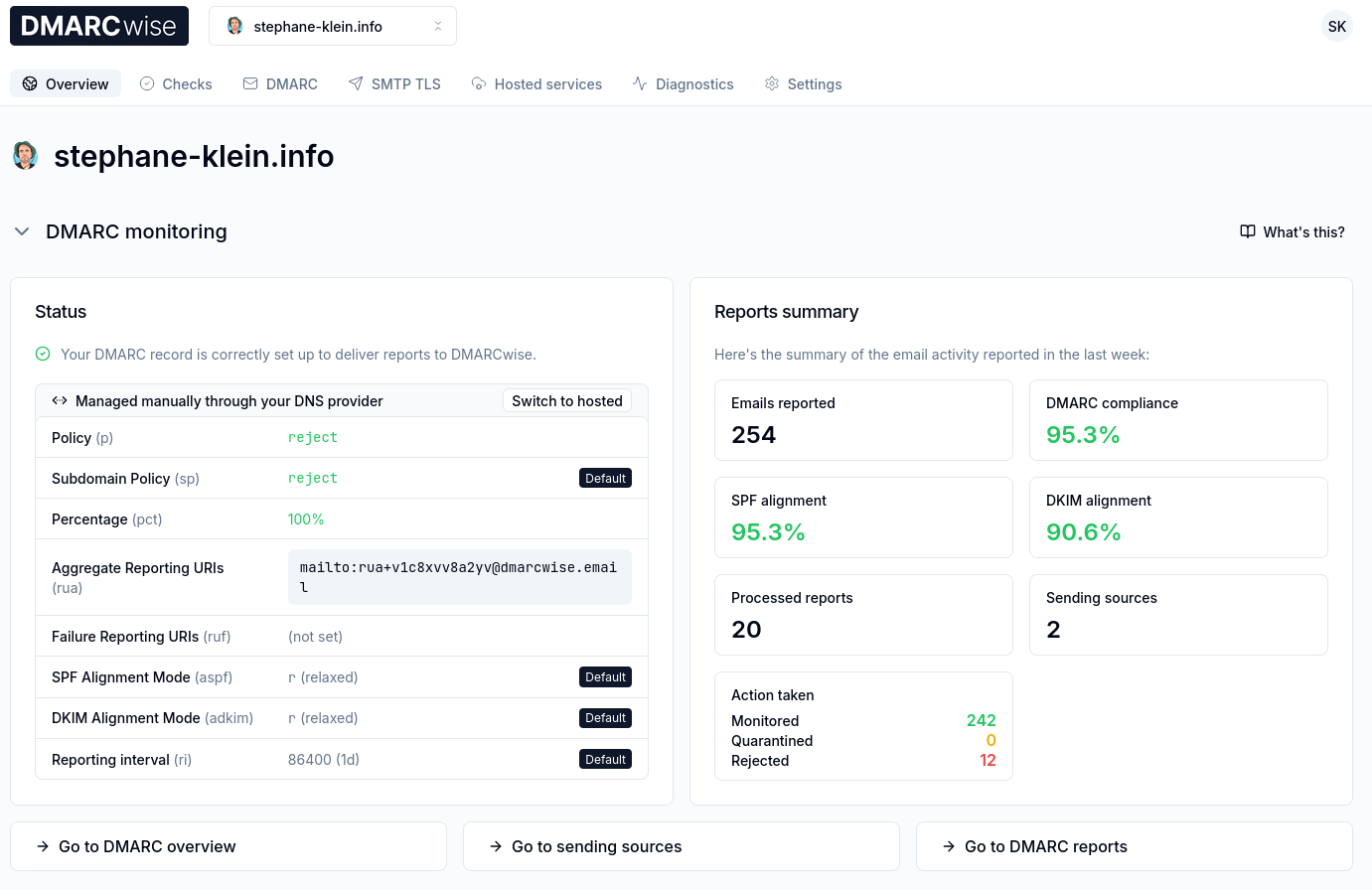
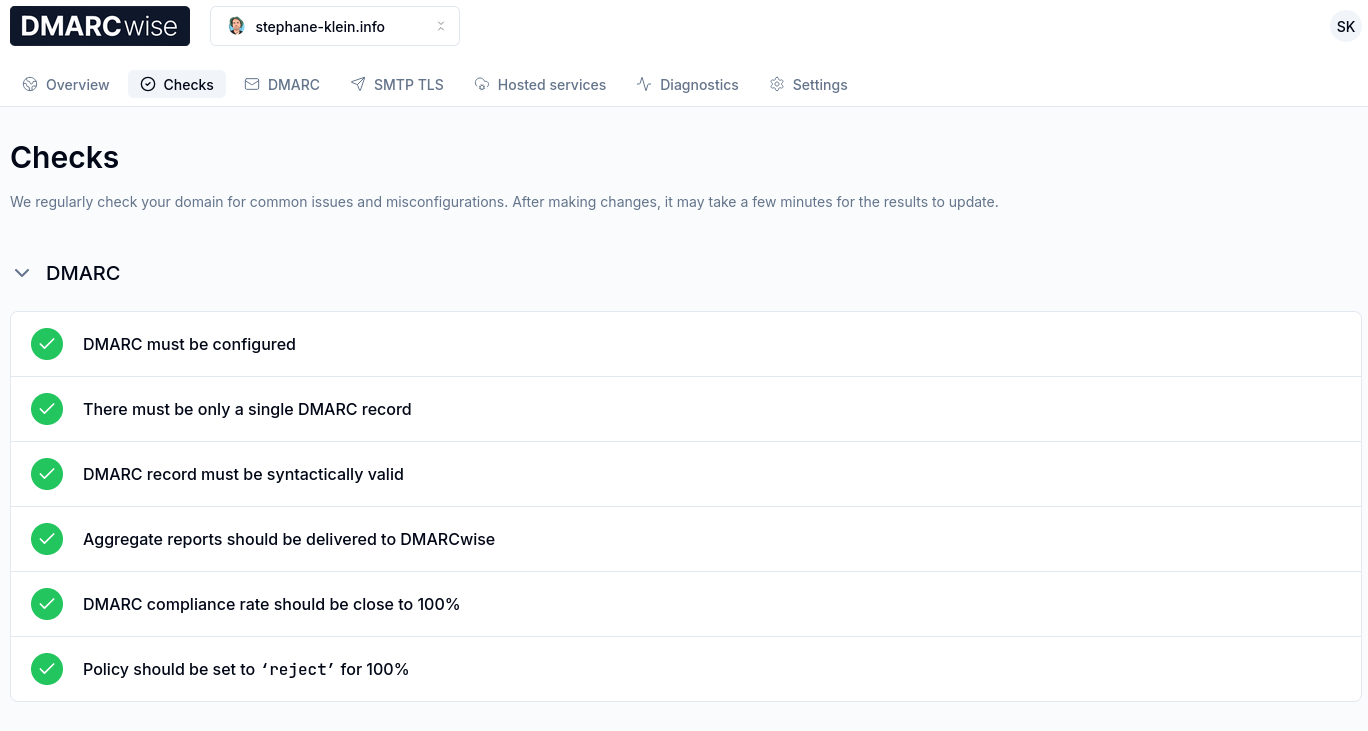
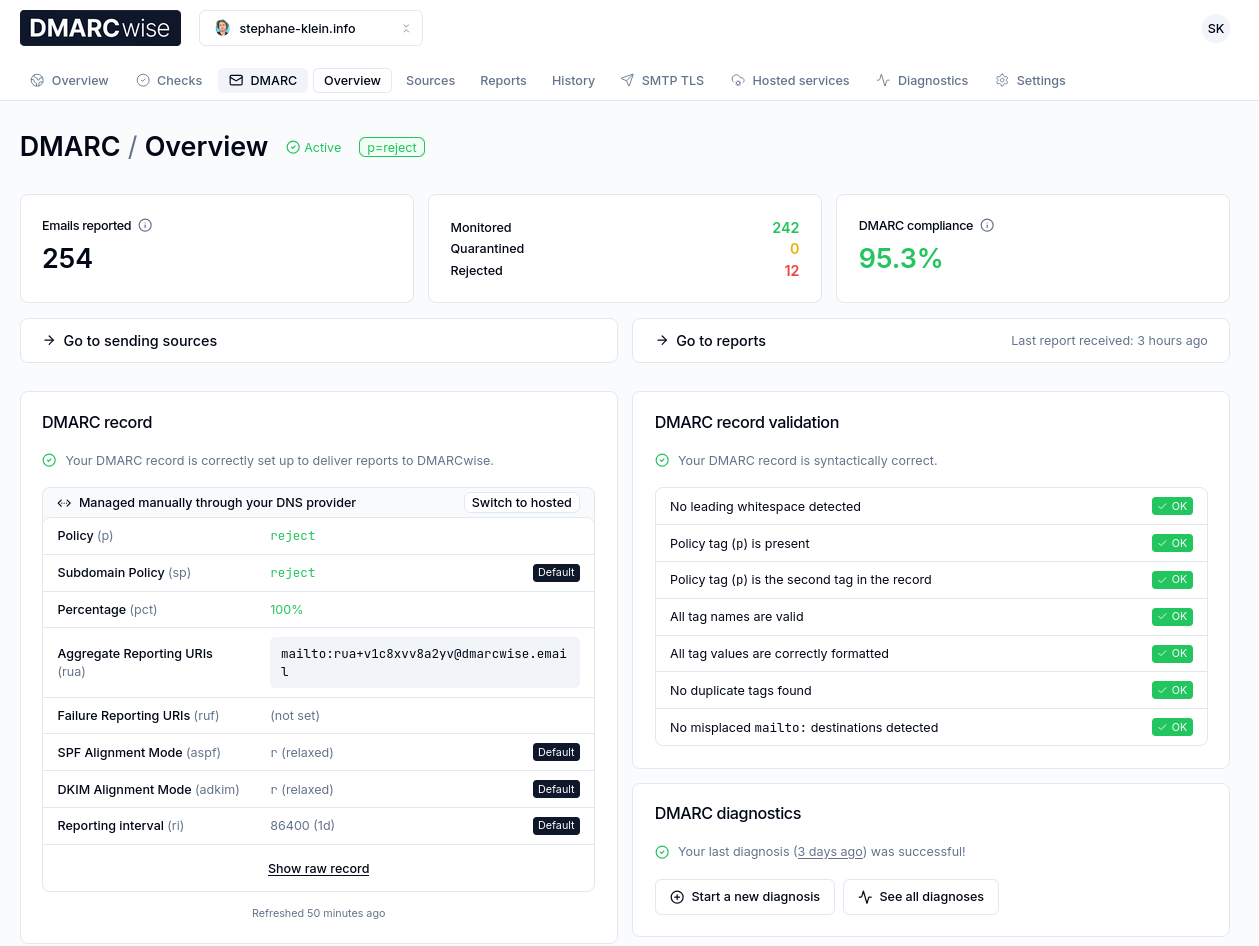
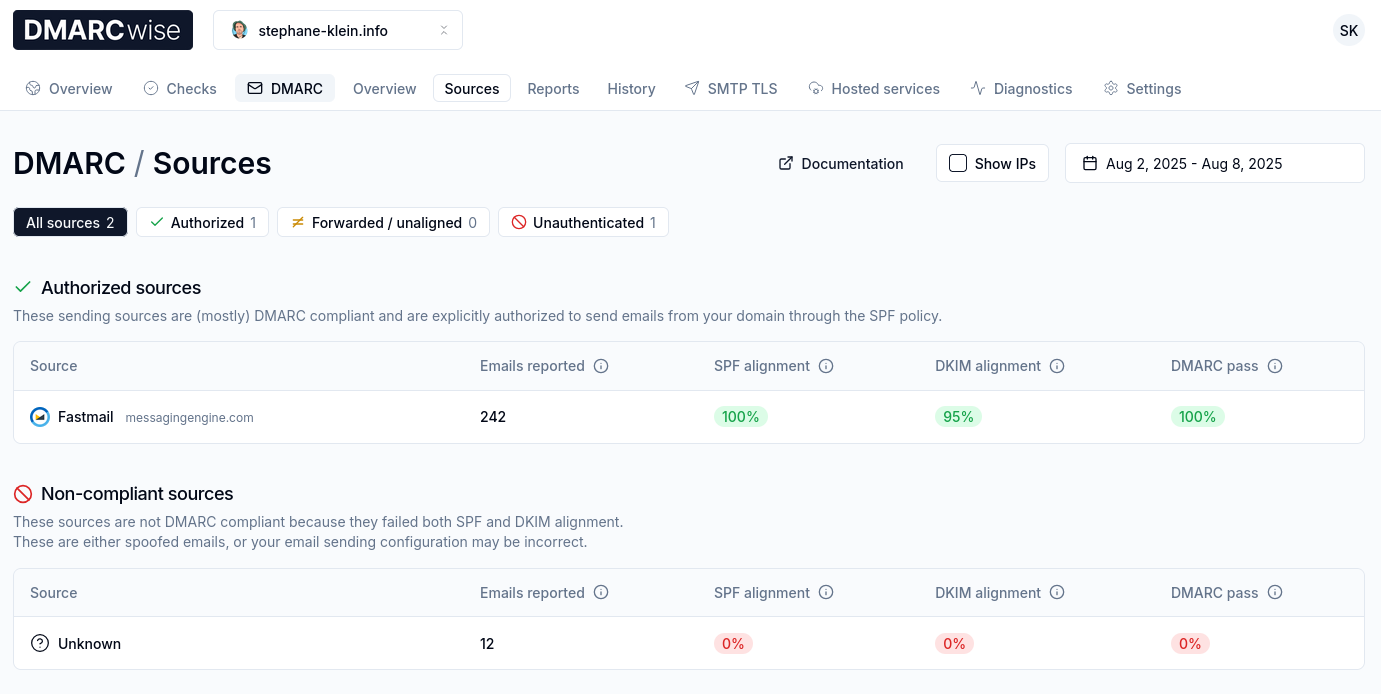
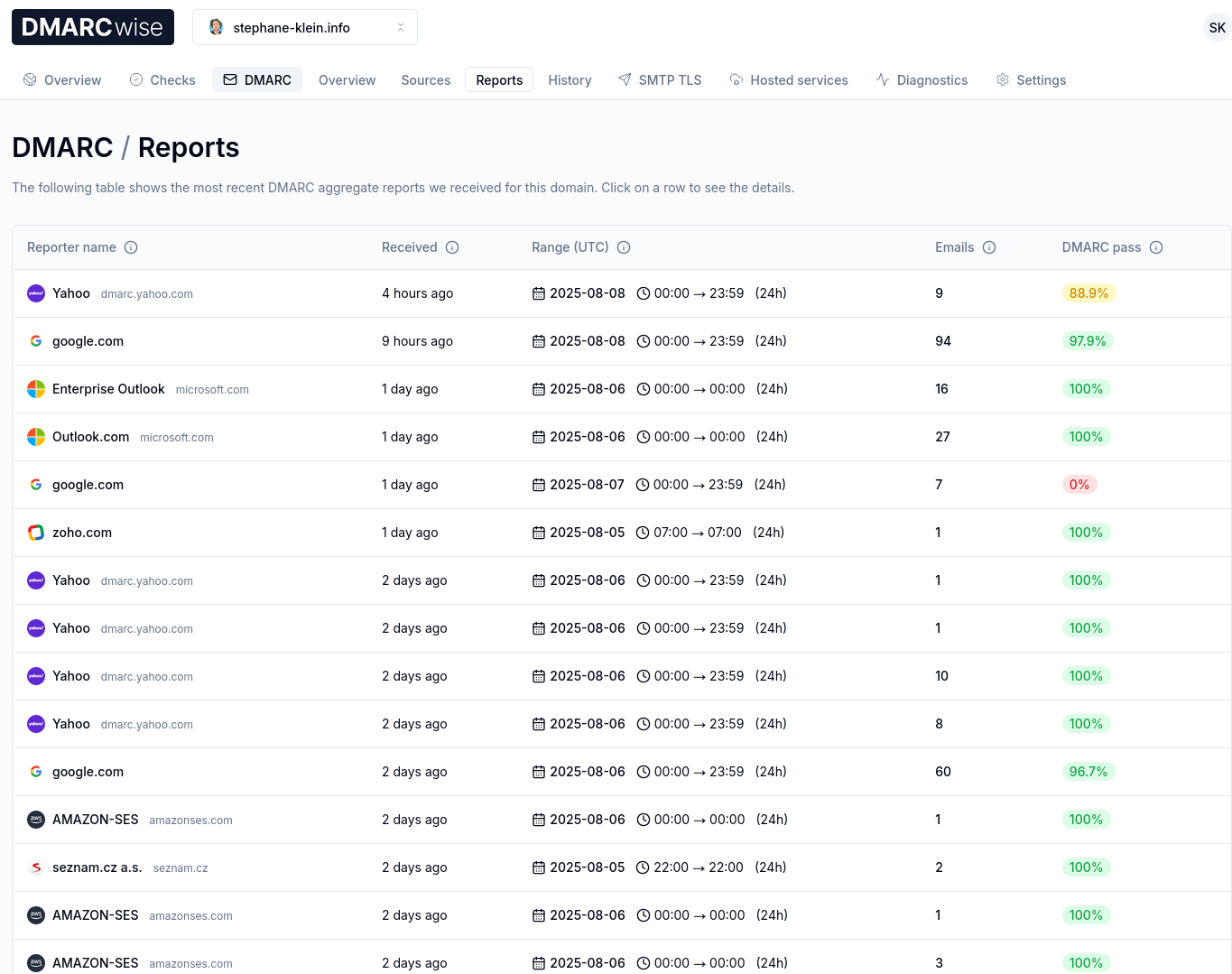
J'ai bien envie de conseiller DMARCwise à mon client.
Je sais qu'il envoie environ 3 millions d'e-mails par mois, ce qui ferait une facture de 1188 € HT par an.
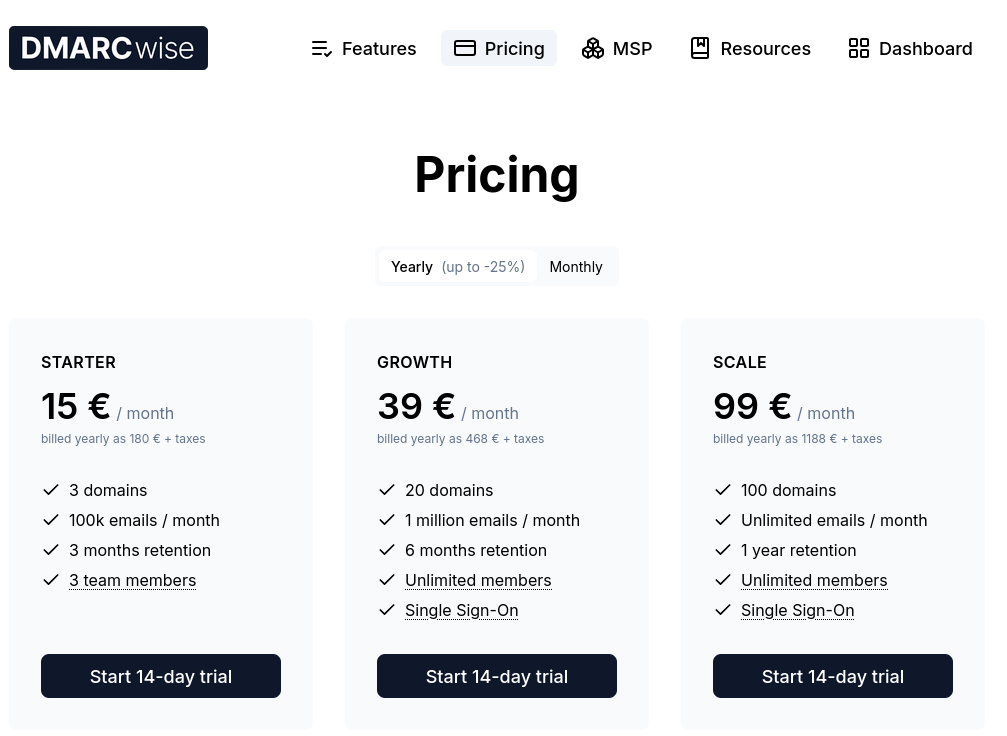
Une autre option serait GlockApps, à $1548 HT par an mais avec une plus 1800 crédit de tests de inbox placement.
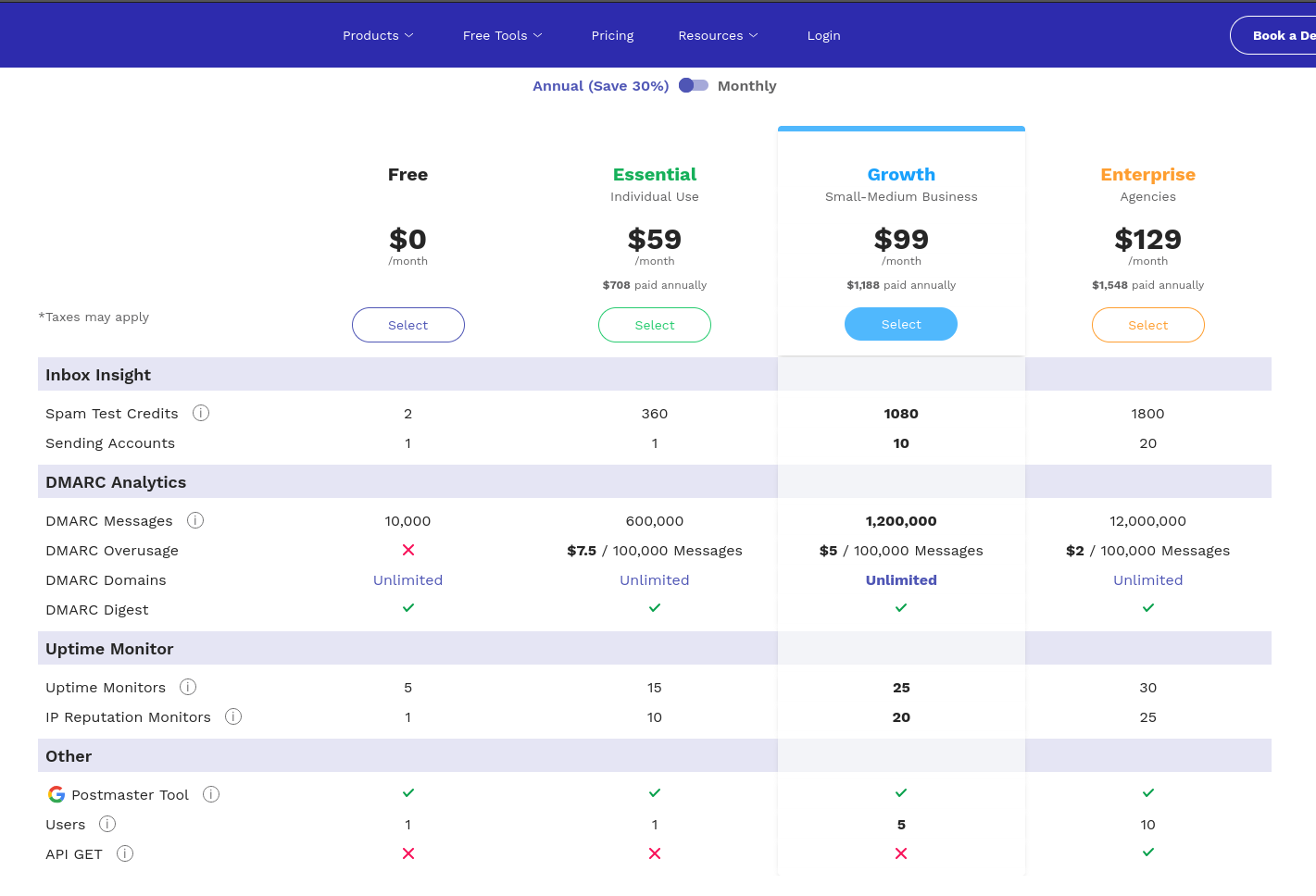
#JaimeraisUnJour prendre le temps de tester le free software de DMARC reporting nommé parsedmarc.
Ma prochaine note sur l'Email deliverability portera probablement sur l'inbox placement.
J'ai découvert la spécification "Brand Indicators for Message Identification"
En travaillant sur une mission freelance d'audit de délivrabilité d'e-mail, #JaiDécouvert la spécification "Brand Indicators for Message Identification".
Il s'agit de la spécification la plus récente qui s'ajoute aux spécifications de lutte contre l'usurpation d'identité email : SPF, DKIM, DMARC, ARC.
BIMI permet d'afficher le logo "certifié" de l'expéditeur du mail dans un certain nombre de clients mails (Apple, Fastmail, Gmail, La Poste, Yahoo).
Par exemple, cela donne ceci pour l'email noreply@notif-colissimo-laposte.info avec mon client mail Fastmail :
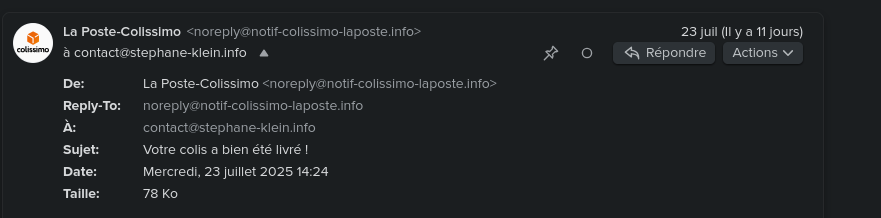
Autre exemple avec Gmail avec le "badge certifié" :
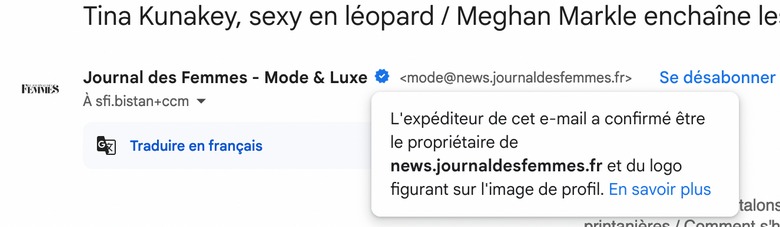
Pour avoir plus d'exemples concrets, je vous conseille de consulter la section [« Quelques exemples d’affichage de BIMI chez les fournisseurs de messagerie »](https://www.badsender.com/guides/bimi-pourquoi-et-comment-le-deployer/#:~:text=les fournisseurs de-,messagerie,-Apple Icloud (Mail) de l'excellent article « Formation BIMI : pourquoi et comment déployer BIMI ? » de l'agence française Badsender, qui offre entre autre des services d'audit de délivrabilité d'e-mail.
Vous pouvez, par exemple, vérifier la configuration BIMI sur cette page, voici le résultat, toujours avec l'adresse mail noreply@notif-colissimo-laposte.info :
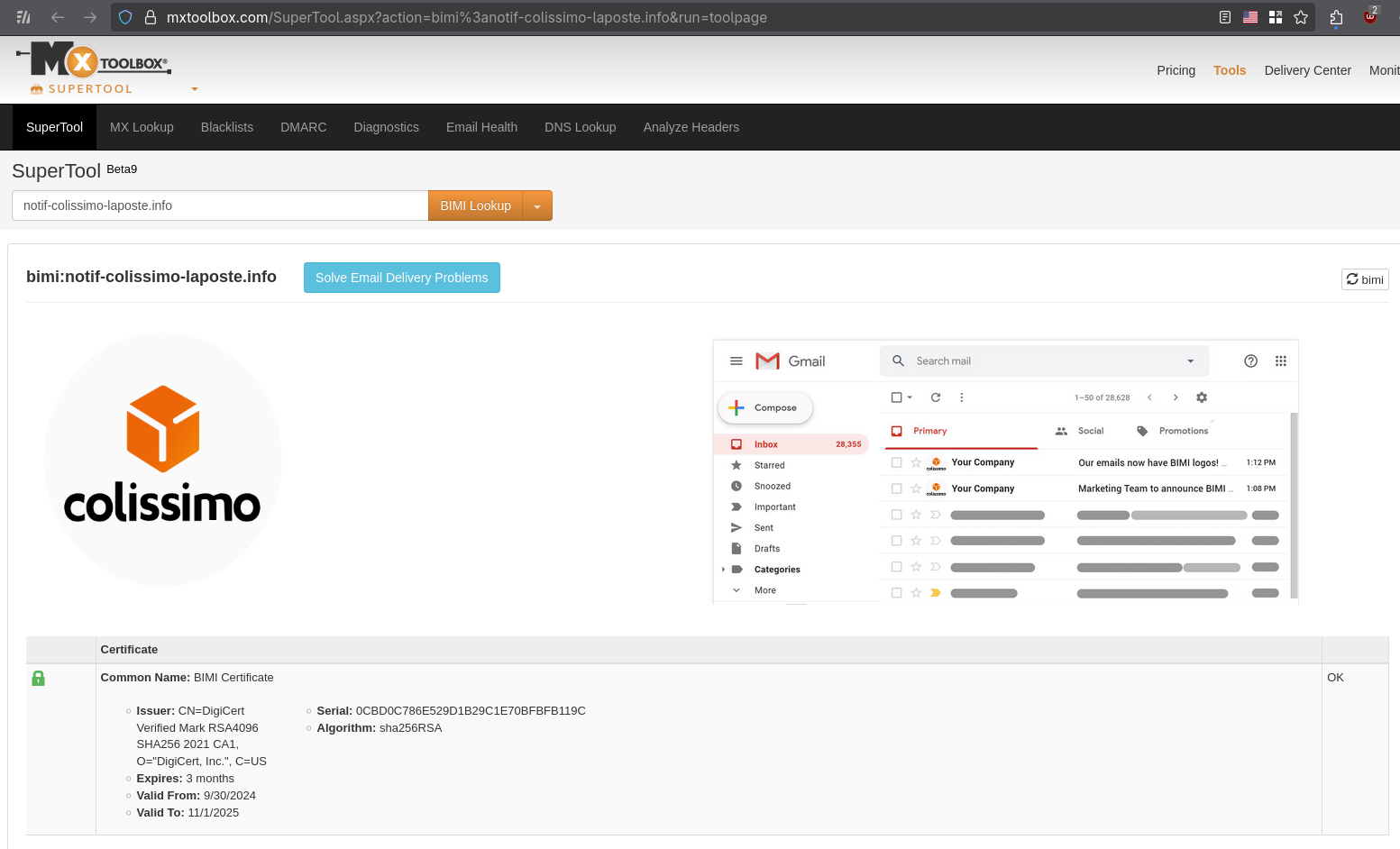
Voici la configuration DNS TXT BIMI du domaine notif-colissimo-laposte.info :
$ dig TXT default._bimi.notif-colissimo-laposte.info +short
"v=BIMI1;l=https://notif-colissimo-laposte.info/logo.svg;a=https://notif-colissimo-laposte.info/la_poste_sa.pem;"
v=BIMI1indique le numéro de version de la spécification.l=https://notif-colissimo-laposte.info/logo.svgcontient l'URL vers le logo au format SVGa=https://notif-colissimo-laposte.info/la_poste_sa.pemcontient l'URL du certificat qui permet de certifier que l'expéditeur d'un email est autorisé à utiliser le logo Colissimo.
Voici ce que contient le certificat :
Issuer: CN=DigiCert Verified Mark RSA4096 SHA256 2021 CA1, O="DigiCert, Inc.", C=US
Expires: 3 months
Valid From: 9/30/2024
Valid To: 11/1/2025
Ce certifact a été généré par DigiCert.
Liste des entreprises de type Mark Verifying Authority pouvant actuellement générer des Verified Mark Certificate ou Common Mark Certificate :
D'après ce que j'ai compris, pour obvenir un Verified Mark Certificate, il est nécessaire de fournir au Mark Verifying Authority une preuve de dépôt de marque, par exemple via l'INPI.
Je pense que "Common" dans Common Mark Certificate est en lien avec le système juridique "Common law". Pour obtenir un Common Mark Certificate, il suffit de prouver qu'on utilise le logo depuis plus de 12 mois. DigiCert indique qu'ils effectuent une vérification en utilisant archive.org.
Depuis fin 2024, un autre type de certificat est disponible. C’est le CMC(Common Mark Certificate). Celui-ci permet de s’affranchir du dépôt de marque. Avoir une marque et un logo déposé sont donc maintenant optionnels. Néanmoins, le certificat CMC ne permet pas de garantir le même niveau de légitimité au destinataire. Certaines messageries, même si elles afficheront le logo BIMI dans le cas d’un certificat CMC n’ajouteront pas de certification de la marque (par exemple, dans Gmail, le checkmark bleu n’est pas affiché en cas de certificat CMC).
Lorsqu’un certificat VMC est choisi, une marque bleue est affichée dans Gmail afin de renforcer le sentiment de légitimité pour le destinataire. Ce qui ne sera pas le cas avec un certificat CMC.
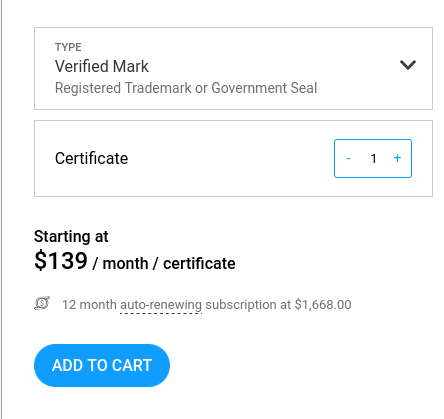
Voici les prix d'un Verified Mark Certificate chez DigiCert : 1668 € par an.
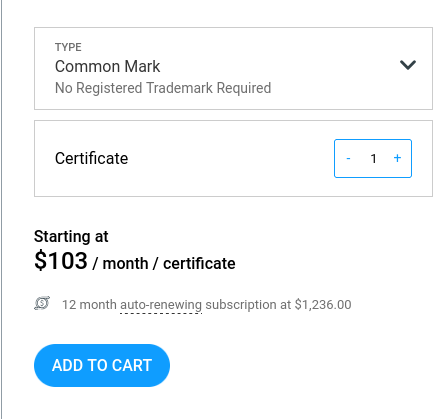
Et 1236 € par an pour un Common Mark Certificate.
Jusqu'à maintenant, je croyais que les services Gravatar ou Libravatar permettaient d'afficher un avatar dans les clients mail, mais je réalise que ce n'est pas le cas et il semble que je ne sois pas le seul à avoir cette idée fausse :
Many users set up their Gravatar expecting it to be shown when sending emails from their email address. This is not always the case, this page explains why.
Truth be told, there aren’t many email clients (meaning the app or platform your users use to read their emails) that support Gravatar. Most popular email services (like Gmail, Outlook or Apple Mail) don’t. Unfortunately there is nothing we can do.
If you have confirmed your reader’s email client support, then there might be some setting (or addon) that your readers will need to tweak.
Je me suis demandé si BIMI pouvait améliorer l'Email deliverability.
En parcourant le Subreddit EmailMarketing, j'ai découvert ce thread : Is BIMI & VMC worth it? . Tous les contributeurs s'accordent à dire que BIMI n'apporte aucune amélioration à l'Email deliverability.
Pour le moment, aucune information ne suggère que BIMI présente un avantage pour l'Email deliverability.
À ce stade, il me semble que la mise en place d'un Verified Mark Certificate est pertinente pour tout service ciblé par des attaques d'arnaque numérique.
Pour les autres services aux moyens limités, je pense qu'investir 1668 € annuels dans un Verified Mark Certificate n'est probablement pas justifié.
Je conseille néanmoins de configurer un logo BIMI sans certificat. Cette approche permet d'améliorer l'User experience en affichant le logo dans les boîtes mail avec un effort minimal.
Je compte configurer prochainement un logo BIMI sans certificat pour mon domaine personnel stephane-klein.info.
Pendant que j'écrivais cette note, je me suis encore interrogé sur l'absence d'acteurs qui tentent d'intégrer correctement une authentification mail via PKI étatique 🤔.
#JaimeraisUnJour creuser cette question dans une note dédiée.
bridge-utils est déprécié, je dois remplacer "brctl" par "ip link"
En étudiant IPv6 et Linux bridge, j'ai découvert que le projet bridge-utils est déprécié. À la place, il faut utiliser iproute2.
Ce qui signifie que je ne dois plus utiliser la commande brctl, chose que j'ignorais jusqu'à ce matin.
iproute2 remplace aussi le projet net-tools. Par exemple, les commandes suivantes sont aussi dépréciées :
ifconfigremplacé parip addretip linkrouteremplacé parip routearpremplacé parip neighbrctlremplacé parip linkiptunnelremplacé parip tunnelnameifremplacé parip link set nameipmaddrremplacé parip maddr
Au-delà des aspects techniques — iproute2 utilise Netlink plutôt que ioctl — l'expérience utilisateur me semble plus cohérente.
J'ai une préférence pour une commande unique ip accompagnée de sous-commandes plutôt que pour un ensemble de commandes disparates.
Cette logique de sous-commandes s'inscrit dans une tendance générale de l'écosystème Linux, et je pense que c'est une bonne direction.
Je pense notamment à systemctl, timedatectl, hostnamectl, localectl, loginctl, apt, etc.
Quand j'ai débuté sous Linux en 1999, j'ai été habitué à utiliser les commande ifup et ifdown qui sont en réalité des scripts bash qui appellent entre autre ifconfig.
Ces scripts ont été abandonnés par les distributions Linux qui sont passées à systemd et NetworkManager.
En simplifiant, l'équivalent des commandes suivantes avec NetworkManager :
$ ifconfig
$ ifup eth0
$ ifdown eth0
est :
$ nmcli device status
$ nmcli connection up <nom_de_connexion>
$ nmcli connection down <nom_de_connexion>
Contrairement à mon intuition initiale, NetworkManager n'est pas un simple "wrapper" de la commande ip d'iproute2.
En fait, nmcli fonctionne de manière totalement indépendante d'iproute2, il utilise l'interface Netlink comme l'illustre cet exemple de la commande nmcli device show :
nmcli device show
↓ (Method call via D-Bus)
org.freedesktop.NetworkManager.Device.GetProperties()
↓ (NetworkManager traite la requête)
nl_send_simple(sock, RTM_GETLINK, ...)
↓ (Socket netlink vers kernel)
Kernel: netlink_rcv() → rtnetlink_rcv()
↓ (Retour des données)
RTM_NEWLINK response
↓ (libnl parse la réponse)
NetworkManager met à jour ses structures
↓ (Réponse D-Bus)
nmcli formate et affiche les données
Autre différence, contrairement à iproute2, les changements effectués par NetworkManager sont automatiquement persistants et il peut réagir à des événements, tel que le branchement d'un câble réseau et la présence d'un réseau WiFi connu.
Les paramètres de configuration de NetworkManager se trouvent dans les fichiers suivants :
- Fichiers de configuration globale de NetworkManager :
# Fichier principal
/etc/NetworkManager/NetworkManager.conf
# Fichiers de configuration additionnels
/etc/NetworkManager/conf.d/*.conf
- Fichiers de configuration des connexions NetworkManager :
# Configurations système (root)
/etc/NetworkManager/system-connections/
# Configurations utilisateur
~/.config/NetworkManager/user-connections/
Comme souvent, Ubuntu propose un outil "maison", nommé netplan qui propose un autre format de configuration. Mais je préfère utiliser nmcli qui est plus complet et a l'avantage d'être la solution mainstream supportée par toutes les distributions Linux.
Idée d'application de réécriture de texte assistée par IA
En travaillant sur mon prompt de reformulation de paragraphes pour mon notes.sklein.xyz, j'ai réalisé que l'expérience utilisateur des chat IA ne semble pas optimale pour ce type d'activité.
Voici quelques idées #idée pour une application dédiée à cet usage :
- Utilisation de deux niveaux de prompt :
- Un niveau général sur le style personnel
- Un niveau spécifique à l'objectif particulier
- Interface à deux zones texte :
- Une zone repliée par défaut contenant le ou les prompts
- Une seconde zone pour le texte à modifier
- Sélection de mots alternatifs comme dans DeepL : une fois qu'un mot de remplacement est choisi, le reste de la phrase s'adapte automatiquement en conservant au maximum la structure originale.
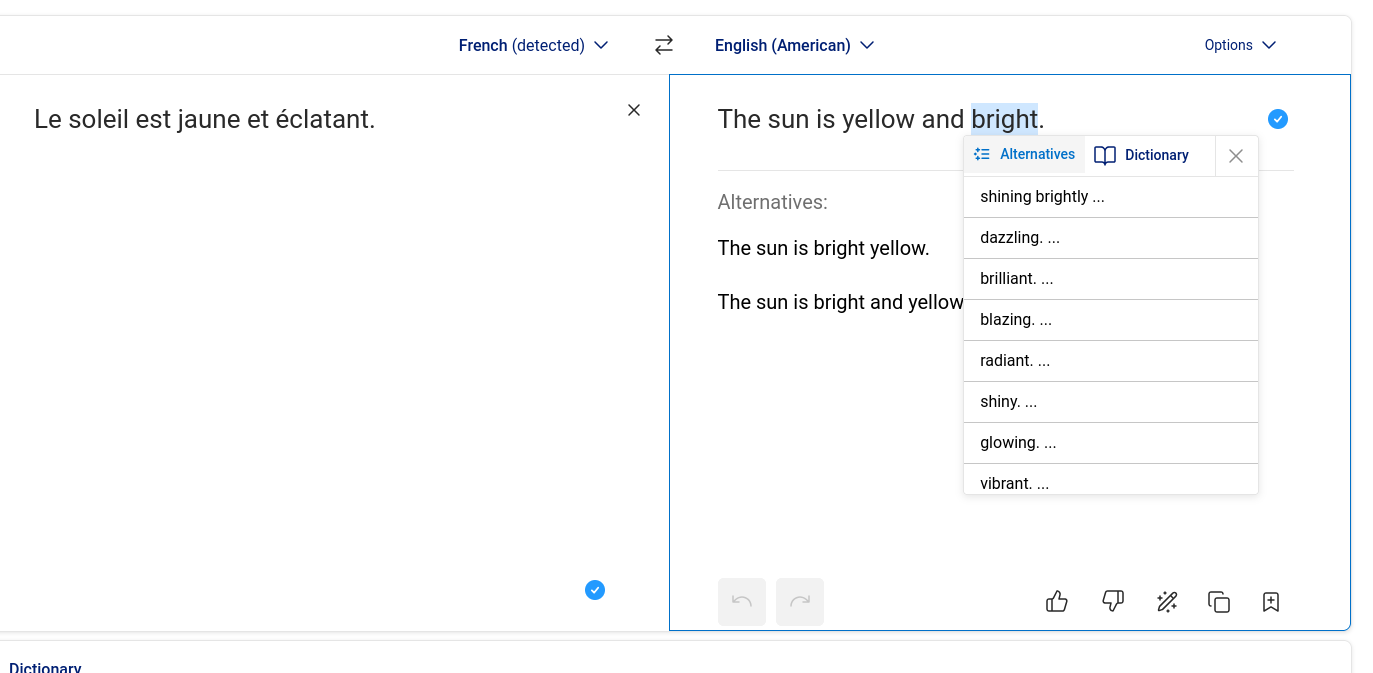
- Sélection flexible : permettre de sélectionner non seulement un mot isolé, mais aussi plusieurs mots consécutifs ou des paragraphes entiers.
- Support parfait du markdown.
À ce jour, je n'ai pas croisé d'application de ce type, #JaimeraisUnJour investir plus de temps pour approfondir cette recherche.
Quelques idées pour implémenter cette application :
- Connecté à OpenRouter
- Utilisation de Svelte, SvelteKit, ProseMirror, PostgreSQL, bits-ui
- Utilisation de la fonctionnalité Structured Outputs (LLM) (https://platform.openai.com/docs/guides/structured-outputs)
Journal du vendredi 17 janvier 2025 à 19:02
D'ici quelques jours, je prévois de rédiger un bilan d'utilisation de avante.nvim pour faire le point sur mon expérience avec cet outil.
Après 5 jours d'utilisation, mon retour est positif. Je trouve avante.nvim très agréable à utiliser et GitHub Copilot avec Claude Sonnet 3.5 m'assiste efficacement 🙂.
Pour le moment, le seul reproche que je peux faire à avante.nvim, c'est que je ne peux pas utiliser Neovim (me balader dans le code, éditer un fichier) pendant qu'une réponse est en train d'être rédigée dans la sidebar.
J'ai trouvé cette issue qui semble correspondre à ce problème : feature: Cursor Movement Issue During Chat Response Generation.
Journal du samedi 21 décembre 2024 à 14:17
Je viens de corriger dans mon sklein-pkm-engine, un problème d'expérience utilisateur que m'avait remonté Alexandre sur la page détail d'une note.
Par exemple sur la note : https://notes.sklein.xyz/2024-12-19_1709/

Le lien sur le tag dev-kit pointait vers https://notes.sklein.xyz/diaries/?tags=dev-kit. Conséquence : les Evergreen Note n'étaient pas listés dans les résultats. Ce comportement était perturbant pour l'utilisateur.
J'ai modifié l'URL sur les tags pour les faire pointer vers https://notes.sklein.xyz/search/?tags=dev-kit, page qui affiche tous types de notes.
Journal du dimanche 03 novembre 2024 à 11:51
Avec la sortie de la version 17 de PostgreSQL, de nouvelles options de sauvegarde sont désormais disponibles : l'outil pg_basebackup (https://www.postgresql.org/docs/17/app-pgbasebackup.html) permet de réaliser les sauvegardes incrémentales, et un nouvel utilitaire, pg_combinebackup, permet de reconstituer une sauvegarde complète à partir de sauvegardes incrémentales.
J'ai lu les articles suivants de Robert Haas, créateur de ces nouvelles fonctionnalités :
- Incremental Backup: What To Copy?
- #JaiDécouvert le projet ptrack.
- Incremental Backups: Evergreen and Other Use Cases
J'en ai profité aussi pour lire :
J'ai trouvé tous ces articles très intéressants, j'y ai appris beaucoup de choses.
Je me demande quel impact ces fonctionnalités auront ou ont déjà sur les outils existants comme pgBackRest, barman, et wal-g.
Autres ressources :
Impact sur pgBackRest ?
Voici ce que j'ai trouvé dans le projet pgBackRest.
We are aware of what's been committed to PG17.
-- from
Je comprends d'après ce commentaire que les auteurs de pgBackRest sont bien au courant des avancées de PostgreSQL 17.
Issue : WAL summarizer in pg 17 and incremental backups in pgbackrest ?.
We already support page-level (we call it block-level) incremental since v2.46 and it works for all versions of PostgreSQL supported by pgBackRest (>= 9.4), see https://pgbackrest.org/user-guide.html#backup/block.
We are planning to use the WAL summarizer to help us pick more optimal block sizes and cross-check timestamps but we are waiting for it to be a bit more stable. Also, the WAL summarizer output uses a lot of memory and is not the best fit for large databases with a lot of changes. We have some ideas on how to make that more efficient but have not had time to pursue it yet.
D'après ce commentaire, je pense avoir compris que les nouvelles fonctionnalités de backup incrémental de PostgreSQL 17 ne sont d'aucune utilité pour pgBackRest, qui implémente déjà cette fonctionnalité de manière efficace 🤔.
Impact sur barman ?
La version 3.11.0 de barman intègre des fonctionnalités liées aux nouvelles fonctionnalités de PostgreSQL 17.
Impact sur wal-g
J'ai n'ai trouvé aucune mention de pg_combinebackup, ni de pg_basebackup incremental dans le repository de wal-g.
J'ai l'impression qu'il est possible d'utiliser directement pg_basebackup pour effectuer des sauvegardes incrémentales de bases de données PostgreSQL. Cependant, je crains que cette idée soit un peu naïve.
Vers la fin de 2023, j'ai commencé à implémenter un POC de pgBackRest : https://github.com/stephane-klein/backlog/issues/322. J'ai pu réaliser une simulation complète de son utilisation dans ce dépôt : poc-pgbackrest. Cependant, je n'ai pas conservé un souvenir précis des raisons pour lesquelles mon expérience utilisateur n'a pas été satisfaisante, ce qui m'a dissuadé de déployer pgBackRest en production.
Après avoir constaté que barman intègre la fonctionnalité increment de pg_basebackup, j'ai envie de tester barman.